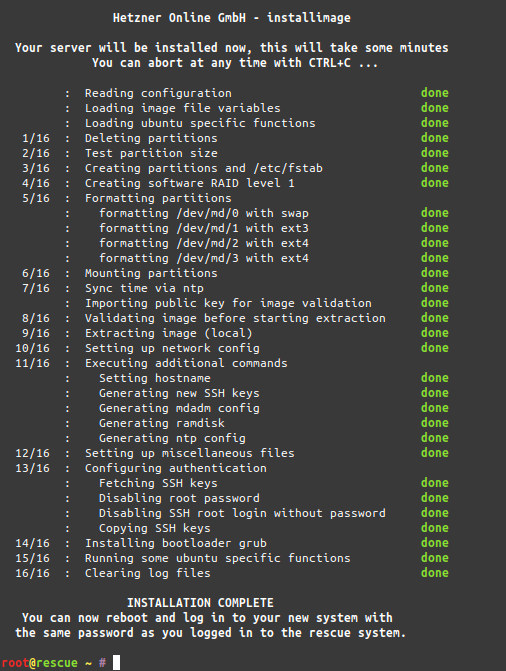
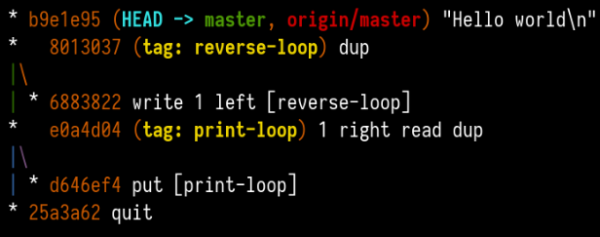
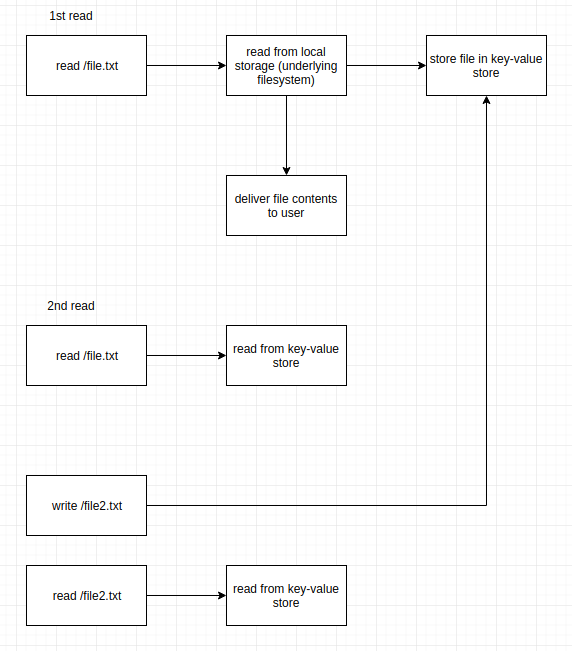
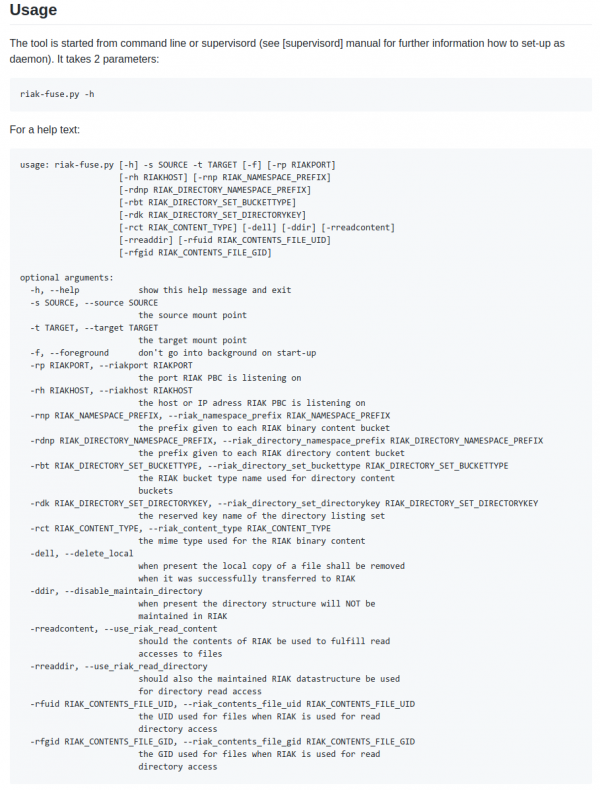
Imagine you’ve got this ancient piece of technology in front of you. You clearly understand how the hardware works and you are even able to emulate the hardware on your modern-world computer.
Unfortunately hardware is only one half of the story. Software is the other half. And software at this time of the past was burned into chips which do not easily give their secret software away.
But let’s start with the hardware:
The IBM 5100 Portable Computer is a portable computer (one of the first) introduced in September 1975, six years before the IBM Personal Computer. It was the evolution of a prototype called the SCAMP (Special Computer APL Machine Portable) that was developed at the IBM Palo Alto Scientific Center in 1973. In January 1978, IBM announced the IBM 5110, its larger cousin, and in February 1980 IBM announced the IBM 5120. The 5100 was withdrawn in March 1982.
When the IBM PC was introduced in 1981, it was originally designated as the IBM 5150, putting it in the “5100” series, though its architecture was not directly descended from the IBM 5100.

And now on to the software:
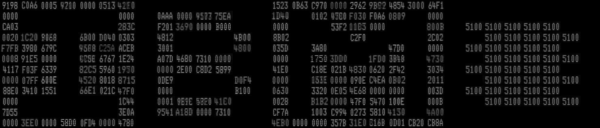
The IBM 5100 portable computer came with some of its built-in programs stored in a read-only memory called the “non-executable ROS”. (ROS = “read-only storage”.) In contrast with the “executable ROS”, which supplies instructions to the 5100’s processor directly, the non-executable ROS is accessed using sequential I/O operations, a bit like a tape.
Most notably, the non-executable ROS holds the interactive interpreters for the APL and BASIC programming languages. These are not “native” 5100 programs but were expressed instead in System/370 mainframe and System/3 minicomputer machine code respectively. The 5100 runs emulator programs for those computers in order to host the interpreters, so perhaps it’s just as well that the non-executable ROS is non-executable.
DATA
So this write-up is all about how the bits where pushed to the screen and recorded as pictures of the said screen. The characters in these pictures then where analyzed and with the help of machine learning the data could be successfully extracted. It is mind-boggling. And it is all on Github.